Machine Learning :Precision and Recall
Model Evaluation Metrics

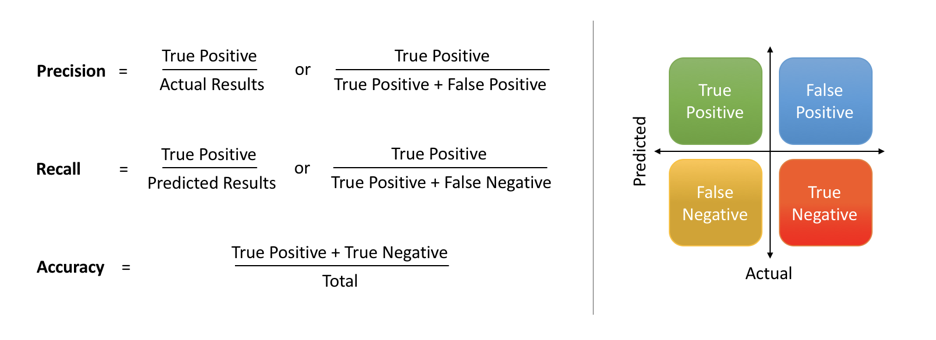
Often, we think that precision and recall both indicate accuracy of the model. While that is somewhat true, there is a deeper, distinct meaning of each of these terms. Precision means the percentage of your results which are relevant. On the other hand, recall refers to the percentage of total relevant results correctly classified by your algorithm. Undoubtedly, this is a hard concept to grasp in the first go.
This is pretty intuitive. If you have to recall everything, you will have to keep generating results which are not accurate, hence lowering your precision. To exemplify this, imagine the case of digital world (again, amazon.com?), wherein there is a limited space on each webpage, and extremely limited attention span of the customer. Therefore, if the customer is shown a lot of irrelevant results and very few relevant results (in order to achieve a high recall), the customer will not keep browsing each and every product forever to finally find the one he or she intends to buy, and will probably switch to Facebook, twitter, or may be Airbnb to plan his or her next vacation. This is a huge loss, and hence the underlying model or algorithm would need a fix to balance the recall and precision.
Does a simpler metric exist?
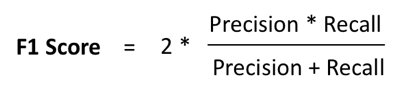
In most problems, you could either give a higher priority to maximizing precision, or recall, depending upon the problem you are trying to solve. But in general, there is a simpler metric which takes into account both precision and recall, and therefore, you can aim to maximize this number to make your model better. This metric is known as F1-score, which is simply the harmonic mean of precision and recall.


Comments
Post a Comment