Machine Learning : Regularization Methods
Over-fitting and Regularization
Machine Learning
In supervised machine learning, models are trained on a subset of data aka training data. The goal is to compute the target of each training example from the training data.
Now, overfitting happens when model learns signal as well as noise in the training data and wouldn’t perform well on new data on which model wasn’t trained on. In the example below, you can see underfitting in first few steps and overfitting in last few.
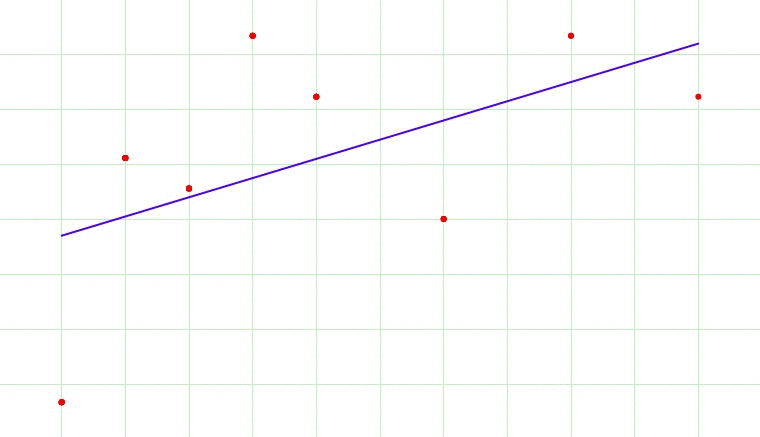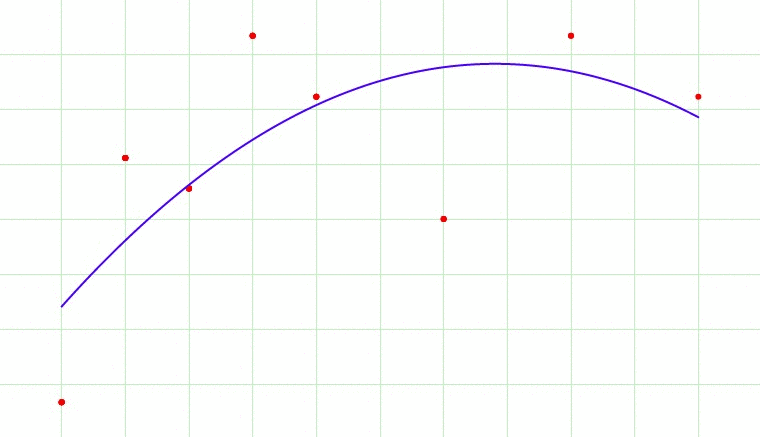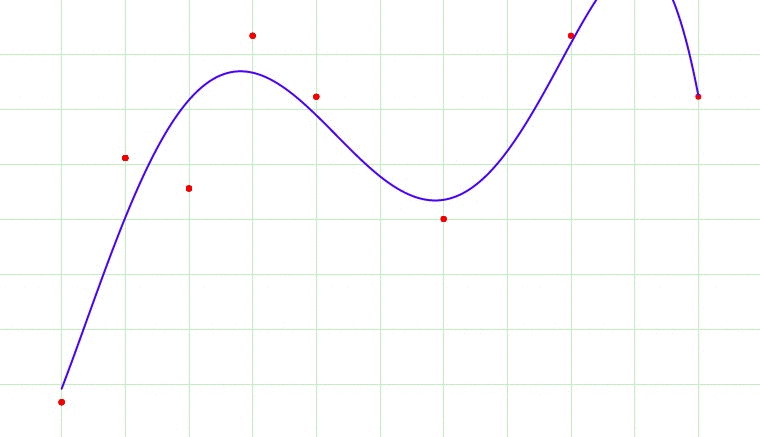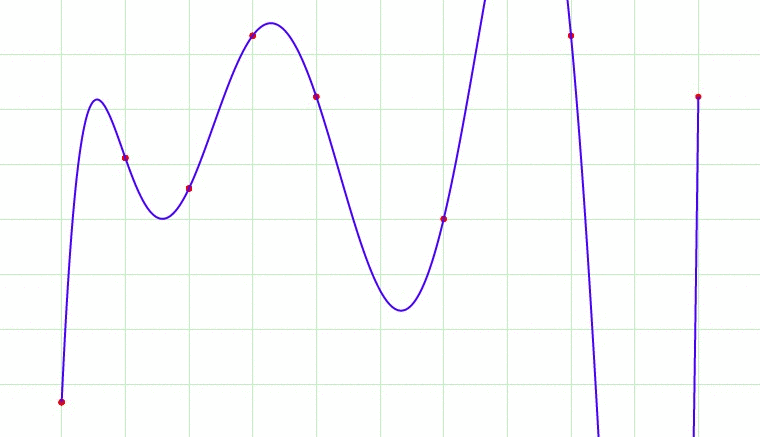
Now, there are few ways you can avoid overfitting your model on training data like cross-validation sampling, reducing number of features, pruning, regularization etc.
Regularization basically adds the penalty as model complexity increases. Regularization parameter (lambda) penalizes all the parameters except intercept so that model generalizes the data and won’t overfit.
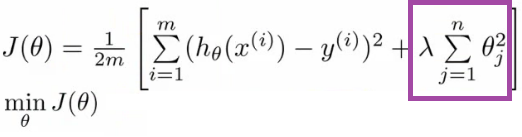
In above gif as the complexity is increasing, regularization will add the penalty for higher terms. This will decrease the importance given to higher terms and will bring the model towards less complex equation.
Stay tuned for the next post which will cover the different type of regularization techniques.
L1 and L2 Regularization Methods
In order to create less complex (parsimonious) model when you have a large number of features in your dataset, some of the Regularization techniques used to address over-fitting and feature selection are:
1. L1 Regularization
2. L2 Regularization
A regression model that uses L1 regularization technique is called Lasso Regression and model which uses L2 is called Ridge Regression.
The key difference between these two is the penalty term.
Ridge regression adds “squared magnitude” of coefficient as penalty term to the loss function. Here the highlighted part represents L2 regularization element.
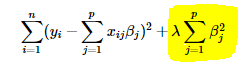 Here, if lambda is zero then you can imagine we get back OLS. However, if lambda is very large then it will add too much weight and it will lead to under-fitting. Having said that it’s important how lambda is chosen. This technique works very well to avoid over-fitting issue.
Here, if lambda is zero then you can imagine we get back OLS. However, if lambda is very large then it will add too much weight and it will lead to under-fitting. Having said that it’s important how lambda is chosen. This technique works very well to avoid over-fitting issue.
Lasso Regression (Least Absolute Shrinkage and Selection Operator) adds “absolute value of magnitude” of coefficient as penalty term to the loss function.
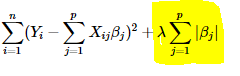 Again, if lambda is zero then we will get back OLS whereas very large value will make coefficients zero hence it will under-fit.
Again, if lambda is zero then we will get back OLS whereas very large value will make coefficients zero hence it will under-fit.
The key difference between these techniques is that Lasso shrinks the less important feature’s coefficient to zero thus, removing some feature altogether. So, this works well for feature selection in case we have a huge number of features.
Traditional methods like cross-validation, stepwise regression to handle overfitting and perform feature selection work well with a small set of features but these techniques are a great alternative when we are dealing with a large set of features.


Comments
Post a Comment