Machine Learning:Multi Label Classification
Q. Difference between Multiclass Classification and Multilabel Classification.?
Overview of Multi-Label Classification:
Problem Definition & Evaluation Metrics:
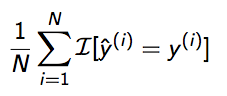
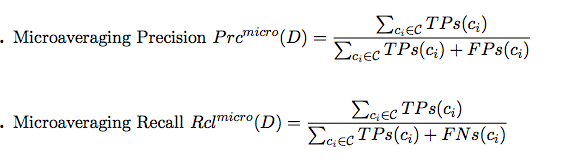
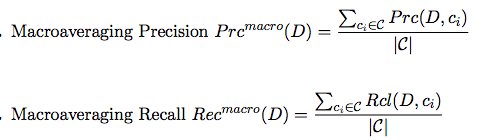
Hamming-Loss (Example based measure):
In simplest of terms, Hamming-Loss is the fraction of labels that are incorrectly predicted, i.e., the fraction of the wrong labels to the total number of labels.
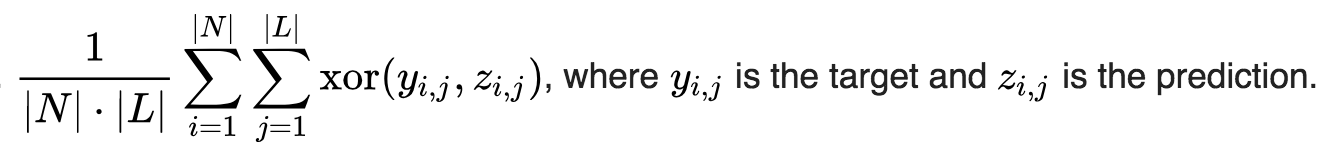
Exact Match Ratio (Subset accuracy):
It is the most strict metric, indicating the percentage of samples that have all their labels classified correctly.

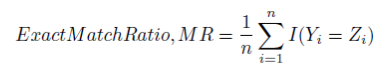
Note: We will be using accuracy_score function to evaluate all our models in this project.
Techniques for Solving a Multi-Label classification problem:
Basically, there are three methods to solve a multi-label classification problem, namely:
- Problem Transformation
- Adapted Algorithm
- Ensemble approaches
4.1 Problem Transformation
In this method, we will try to transform our multi-label problem into single-label problem(s).
This method can be carried out in three different ways as:
- Binary Relevance
- Classifier Chains
- Label Powerset
4.1.1 Binary Relevance
This is the simplest technique, which basically treats each label as a separate single class classification problem.
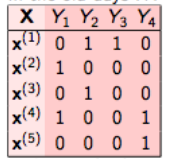
For example, let us consider a case as shown below. We have the data set like this, where X is the independent feature and Y’s are the target variable.
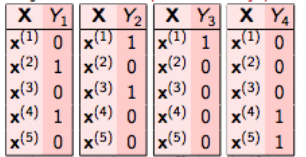
4.1.2 Classifier Chains
In this, the first classifier is trained just on the input data and then each next classifier is trained on the input space and all the previous classifiers in the chain.
Let’s try to this understand this by an example. In the dataset given below, we have X as the input space and Y’s as the labels.
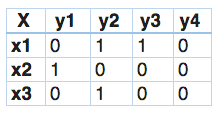
In classifier chains, this problem would be transformed into 4 different single label problems, just like shown below. Here yellow colored is the input space and the white part represent the target variable.

This is quite similar to binary relevance, the only difference being it forms chains in order to preserve label correlation. So, let’s try to implement this using multi-learn library.
4.1.3 Label Powerset
In this, we transform the problem into a multi-class problem with one multi-class classifier is trained on all unique label combinations found in the training data.
Let’s understand it by an example.
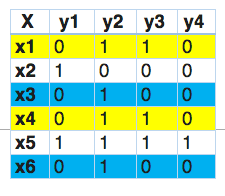
In this, we find that x1 and x4 have the same labels, similarly, x3 and x6 have the same set of labels. So, label powerset transforms this problem into a single multi-class problem as shown below.
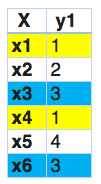
So, label powerset has given a unique class to every possible label combination that is present in the training set.
4.2 Adapted Algorithm
Adapted algorithm, as the name suggests, adapting the algorithm to directly perform multi-label classification, rather than transforming the problem into different subsets of problems.
For example, multi-label version of kNN is represented by MLkNN. So, let us quickly implement this on our randomly generated data set.
4.3 Ensemble Approaches
Ensemble always produces better results. Scikit-Multilearn library provides different ensembling classification functions, which you can use for obtaining better results.
5. Case Studies
Multi-label classification problems are very common in the real world. So, let us look at some of the areas where we can find the use of them.
1. Audio Categorization
We have already seen songs being classified into different genres. They are also been classified on the basis of emotions or moods like “relaxing-calm”, or “sad-lonely” etc.
Source: link
2. Image Categorization
Multi-label classification using image has also a wide range of applications. Images can be labeled to indicate different objects, people or concepts.

3. Bioinformatics
Multi-Label classification has a lot of use in the field of bioinformatics, for example, classification of genes in the yeast data set.
It is also used to predict multiple functions of proteins using several unlabeled proteins. You can check this paper for more information.
4. Text Categorization
You all must once check out google news. So, what google news does is, it labels every news to one or more categories such that it is displayed under different categories. For example, take a look at the image below.
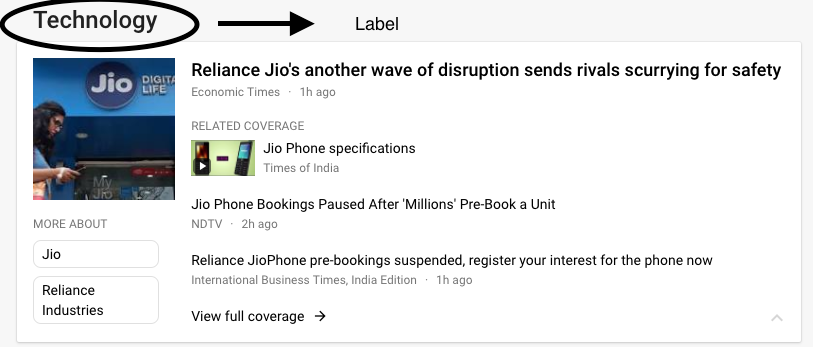
That same news is present under the categories of India, Technology, Latest etc. because it has been classified into these different labels. Thus making it a multi label classification problem.
There are plenty of other areas, so explore and comment down below if you wish to share it with the community.
6. End Notes
In this article, I introduced you to the concept of multi-label classification problems. I have also covered the approaches to solve this problem and the practical use cases where you may have to handle it using multi-learn library in python.
I hope this article will give you a head start when you face these kinds of problems. If you have any doubts/suggestions, feel free to reach out to me below!


Comments
Post a Comment