Machine Learning:Random forest Classification & Regression
Random Forest Classifier :
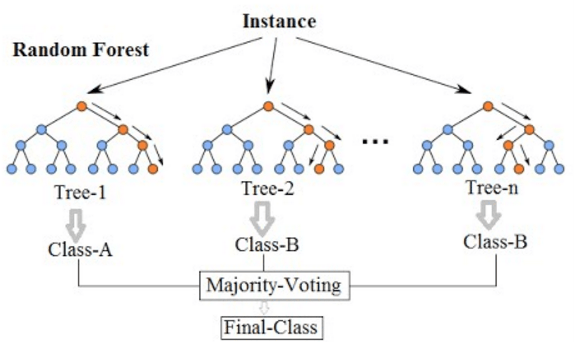
It is an ensemble tree-based learning algorithm. The Random Forest Classifier is a set of decision trees from randomly selected subset of training set. It aggregates the votes from different decision trees to decide the final class of the test object.
Ensemble Algorithm :
Ensemble algorithms are those which combines more than one algorithms of same or different kind for classifying objects. For example, running prediction over Naive Bayes, SVM and Decision Tree and then taking vote for final consideration of class for test object.
Types of Ensemble Learning:
- Boosting.
- Bootstrap Aggregation (Bagging).
1. Boosting:
Boosting refers to a group of algorithms that utilize weighted averages to make weak learners into stronger learners. Boosting is all about “teamwork”. Each model that runs, dictates what features the next model will focus on.
In boosting as the name suggests, one is learning from other which in turn boosts the learning.
2. Bootstrap Aggregation (Bagging):
Bootstrap refers to random sampling with replacement. Bootstrap allows us to better understand the bias and the variance with the dataset. Bootstrap involves random sampling of small subset of data from the dataset.
It is a general procedure that can be used to reduce the variance for those algorithm that have high variance, typically decision trees. Bagging makes each model run independently and then aggregates the outputs at the end without preference to any model.
Problems with Decision Trees :
Decision trees are sensitive to the specific data on which they are trained. If the training data is changed the resulting decision tree can be quite different and in turn the predictions can be quite different.
Also Decision trees are computationally expensive to train, carry a big risk of overfitting, and tend to find local optima because they can’t go back after they have made a split.
To address these weaknesses, we turn to Random Forest :) which illustrates the power of combining many decision trees into one model.
Why Decison Tree Lead to Overfitting.?
During the construction of a decision tree, also referred to as tree induction, the tree repeatedly splits the data in a node in order to get successively paired subsets of data. Note that a decision tree classifier can potentially expand its nodes until it can perfectly classify samples in the training data. But if the tree grows nodes to fit the noise in the training data, then it will not classify a new sample well. This is because the tree has partitioned the input space according to the noise in the data instead of to the true structure of a data. In other words, it has overfit
How Can Overfitting be avoided in Decision Trees.?
There are two ways.
- One is to stop growing the tree before the tree is fully grown to perfectly fit the training data. This is referred to as pre-pruning
- The other way to avoid overfitting in decision trees is to grow the tree to its maximum size and then prune the tree back by removing parts of the tree. This is referred to as post-pruning.
In general, overfitting occurs because the model is too complex.
With pre-pruning, the idea is to stop tree induction before a fully grown tree is built that perfectly fits the training data. To do this, restrictive stopping conditions for growing nodes must be used.
- For example, a nose stops expanding if the number of samples in the node is less than some minimum threshold.
- Another example is to stop expanding a note if the improvement in the impurity measure falls below a certain threshold.
In post-pruning, the tree is grown to its maximum size, then the tree is pruned by removing nodes using a bottom up approach. That is, the tree is trimmed starting with the leaf nodes
The pruning is done by replacing a subtree with a leaf node if this improves the generalization error, or if there is no change to the generalization error with this replacement.
In other words, if removing a subtree does not have a negative effect on the generalization error, then the nodes in that subtree only add to the complexity of the tree, and not to its overall performance. So those nodes should be removed.
In practice, post-pruning tends to give better results. This is because pruning decisions are based on information from the full tree.
Random Forest:
Random forest is a bagging technique and not a boosting technique. The trees in random forests are run in parallel. There is no interaction between these trees while building the trees.
It operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees.
A random forest is a meta-estimator (i.e. it combines the result of multiple predictions) which aggregates many decision trees, with some helpful modifications:
- The number of features that can be split on at each node is limited to some percentage of the total (which is known as the hyperparameter). This ensures that the ensemble model does not rely too heavily on any individual feature, and makes fair use of all potentially predictive features.
- Each tree draws a random sample from the original data set when generating its splits, adding a further element of randomness that prevents overfitting.
The above modifications help prevent the trees from being too highly correlated.
Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2. Random Forest Prediction for a regression problem:
f(x) = sum of all sub-tree predictions divided over B trees
An Example of Random Forest Classification :
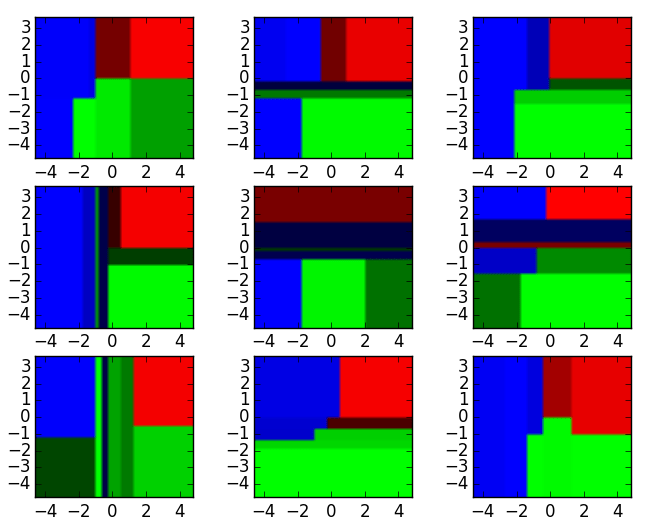
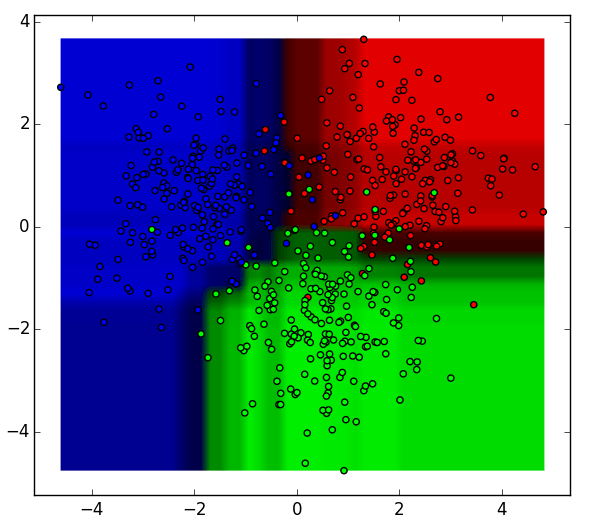
Resultant from above 9 classifier :
The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right). The horizontal and vertical axes of the above decision tree outputs can be thought of as features x1 and x2. At certain values of each feature, the decision tree outputs a classification of “blue”, “green”, “red”, etc.
These above results are aggregated, through model votes or averaging, into a single
ensemble model that ends up outperforming any individual decision tree’s output.
Features and Advantages of Random Forest :
- It is one of the most accurate learning algorithms available. For many data sets, it produces a highly accurate classifier.
- It runs efficiently on large databases.
- It can handle thousands of input variables without variable deletion.
- It gives estimates of what variables that are important in the classification.
- It generates an internal unbiased estimate of the generalization error as the forest building progresses.
- It has an effective method for estimating missing data and maintains accuracy when a large proportion of the data are missing.
Disadvantages of Random Forest :
- Random forests have been observed to overfit for some datasets with noisy classification/regression tasks.
- For data including categorical variables with different number of levels, random forests are biased in favor of those attributes with more levels. Therefore, the variable importance scores from random forest are not reliable for this type of data.
Comments
Post a Comment